Tag: Internet
J’ai besoin d’une appli web rapidement
Voici les slides de la présentation sur le développement rapide d'applications web sur la JVM que j'ai fait jeudi dernier pour le FinistJUG :
Angry Citizens

Il y a quelque temps un collègue de travail m'avait demandé un dessin pour l'association Le Drennec ADSL, qui se batte pour obtenir la couverture du Drennec en ADSL, à la place du projet WiMAX poussé par la municipalité (technologiquement dépassé, économiquement pas intéressant et surtout ne répondant pas au vrai besoin).
Leur objectif est l'installation d'un nœud de raccordement d'abonnés en zone d'ombre (NRA-ZO), terme barbare derrière lequel il se cache un petit répartiteur ADSL local, lié par fibre optique au répartiteur principal le plus proche (à Plabennec dans le cas du Drennec). Aujourd'hui la technologie WiMAX, même si on met de côté toute considération de santé publique ou son instabilité face aux conditions climatiques, ne répond pas au vrai besoin, car elle est incapable de fournir du vrai haut débit, limitant les liaisons à 2 mbit/s.
Même si mon collègue Bruno m'avait fourni les grandes lignes du dessin qu'il voulait, j'avais du mal à trouver une idée qui me plaise. Il fallait bien représenter l'opposition qui se vit entre ce groupe de citoyens du Drennes et une municipalité enfermée dans leur vision des choses et refusant de comprendre les enjeux et l'importance d'internet dans le monde d'aujourd'hui.
Et un soir, en jouant à Angry Birds, j'ai trouvé l'inspiration qui manquait. Quelques coups d'Inkscape après, j'ai fait ma propre version du conflit entre citoyens et municipalité :

Après je l'ai retravaillé, pour l'adapter à la demande de l'association, pour aboutir sur le dessin à trois panneaux que vous pouvez voir sur le site de Le Drennec ADSL.
Firefox 4.0 bêta 1
Ca y est, la première beta de Firefox 4 est officiellement sortie avant-hier. Je l'ai installé hier sur mon Ubuntu, et il faut dire que ça tourne vraiment bien. Je l'ai testé avec mon pattern de navigation habituel (quelques 80 onglets...) et c'est rapide, très stable et plus légère que Firefox 3.
Pour les nouveautés de cette version, tout colle avec l'information qui avait été communiqué en mai dernier :

Pour l'utilisateur final, les principales différences seront donc une meilleur performance, une navigation plus rapide, une interface simplifié (certains disent "à la Chrome") et un gestionnaire d'identités pour faciliter l'accès aux sites et réseaux sociaux desquels il en est membre, tout en gardant le contrôle sur les données transmis à ces sites.
Pour le développeur web les améliorations sont multiples : support de HTML5, CSS3 et websockets, multimédia natif (<video>, <audio>, <canvas>...) et des outils pour aide au développeur (web console, web inspector, nouveau profile manager, diagnostique de mémoire...)
Si on ajoute à cela des améliorations sur le moteur (interpréteur JS plus rapide, meilleure réponse de interface, gestion de l'arbre DOM améliorée), un modèle de privilèges revu pour donner plus de stabilité et de l'accélération graphique, on devrait avoir un navigateur vraiment hors série.
Du côté du support des derniers technologies web, chez Mozilla ils ont préparé une liste plutôt exhaustive des de l'état de ce Firefox 4.0 bêta 1 par rapport aux précédentes versions de Firefox, avec des catégories allant du HTML 5 aux outils de développement, en passant par l'API pour les fichiers, la gestion des plugins ou le JavaScript.

Sur la bêta en elle même, une des nouveautés les plus sympathiques est l'ajout d'un bouton Feedback pour faire des retours de votre expérience avec Firefox 4.0b1 aux développeurs de chez Mozilla.

Malheureusement, une des nouveautés que j'avais le plus envie de voir, la nouvelle interface, n'est pas disponible sur Linux dans cette première bêta, il faudra attendre la deuxième dans quelques semaines.

Vous pouvez donc trouver Firefox 4.0 bêta 1 sur le site de Mozilla, en plus de soixante langages et pour Linux, Windows et Mac.
Comme d'habitude, je ne manquerai pas de vous raconter mes impressions après l'avoir utilisé de façon un peu intensive les prochains jours. Et oui, je crois que, encore une fois, c'est parti pour une série de billets sur Firefox...
Je peux entendre déjà le soupir et le "et ça recommence" au fond... Et oui, je suis un fanboy de Firefox, je peux pas m'empêcher... mais j'assume :wink_ee:
Pourquoi je préfère Google à Bing

Une des raisons pour lesquelles je préfère Google à Bing, c'est que chez Google ils ont compris leurs utilisateurs, et ils offrent ce que les utilisateurs espèrent trouver.
Ce n'est pas une question d'avoir des algorithmes de recherche plus performants, ou même de la pertinence des résultats, ça va plus loin. C'est la mise en forme des résultats, le fait d'essayer d'anticiper, en fonction de la recherche fait par l'utilisateur, la présentation optimale des résultats.
Bing pour l'instant est un moteur de recherche semblable à celui de Google il y a quelques années, il se limite à essayer d'amener des informations pertinentes correspondantes à la recherche (et c'est déjà bien !). Google a dépassé cet état et il cherche maintenant à deviner ce que l'utilisateur voudrait savoir lorsqu'il a écrit une requête dans la fenêtre de navigateur, et à le fournir cette information directement.
Des exemples il y a par dizaines, mais celui que j'ai trouvé ce matin est assez explicite. Il suffit de chercher "Coupe du Monde" dans les deux moteurs :
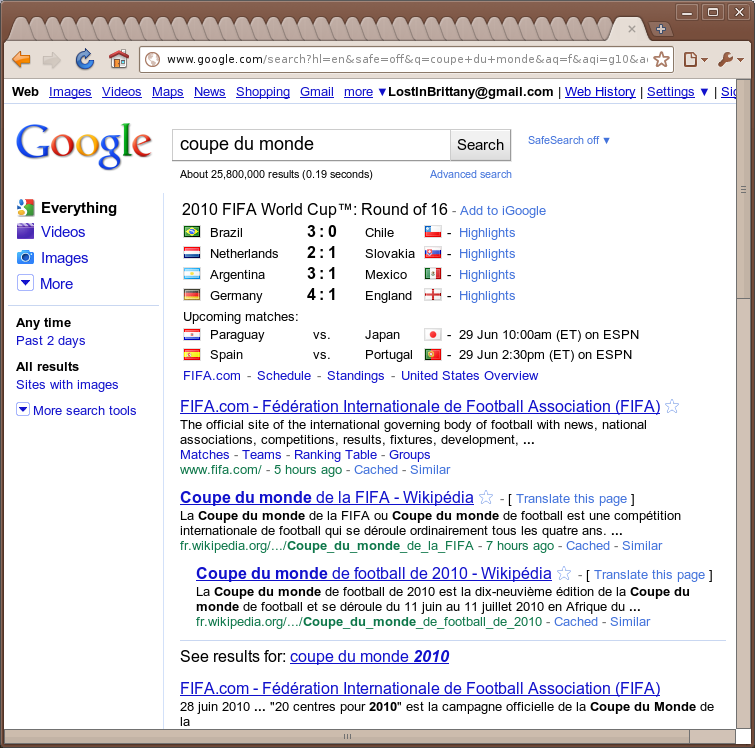
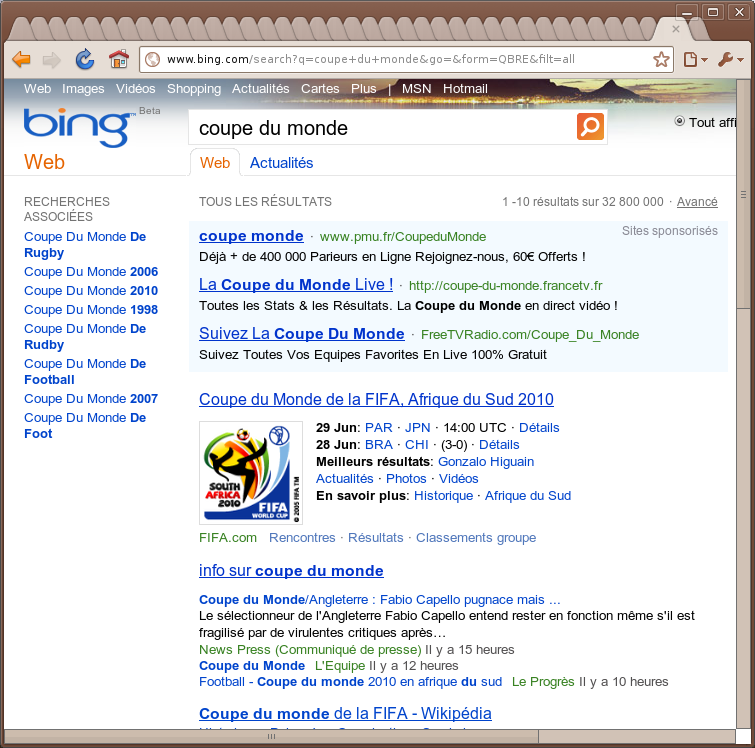
Si comme une bonne partie de la population, je recherche simplement les résultats des matchs de hier, chez Google je n'ai pas besoin de cliquer nulle part, les résultats sont directement là, clairs et nets. Chez Bing, bien, c'est pas ça encore...
On commence à savoir plus sur Firefox 4
L'arrivée de Firefox 4, la prochaine version du navigateur de Mozilla, commence à se profiler dans l'horizon. La première bêta sortira le mois prochain, pour une sortie prévue de la version définitive courant novembre.
On savait déjà les objectifs affichés de cette nouvelle version, être un navigateur rapide, puissant et qui donne à l'utilisateur un contrôle complète de son expérience web (navigation, données, vie privée...). Mais cela manquait forcement un peu de concret.
Lundi dernier, Mike Beltzner (Directeur de Firefox chez Mozilla), a levé un peu le voile avec une présentation du plan de produit pour Firefox 4 :

Pour l'utilisateur final, les principales différences seront donc une meilleur performance, une navigation plus rapide, une interface simplifié (certains disent "à la Chrome") et un gestionnaire d'identités pour faciliter l'accès aux sites et réseaux sociaux desquels il en est membre, tout en gardant le contrôle sur les données transmis à ces sites.

Pour le développeur web les améliorations sont multiples : support de HTML5, CSS3 et websockets, multimédia natif (<video>, <audio>, <canvas>...) et des outils pour aide au développeur (web console, web inspector, nouveau profile manager, diagnostique de mémoire...)
Si on ajoute à cela des améliorations sur le moteur (interpréteur JS plus rapide, meilleure réponse de interface, gestion de l'arbre DOM améliorée), un modèle de privilèges revu pour donner plus de stabilité et de l'accélération graphique, on devrait avoir un navigateur vraiment hors série.
J'attends donc avec impatience la sortie de la bêta le mois prochain...
Arrêt Sur Images et les droits d'auteur

Les journalistes se plaignent souvent de comment les internautes en général, et les blogueurs en particulier, ne respectent pas les droits d'auteur. Ils se disent pillés par les internautes, par Google, par tout le monde. Des fois ils ont raison, mais souvent c'est juste l'inverse qui se passe...
Je tenais à Arrêt Sur Images (ASI) pour l'un des rares média qui avaient compris internet, qui ont une certaine connaissance du net, un certain savoir faire. Maintenant j'ai des doutes.
Car dans un des articles du 6 avril 2010, dans la version abonnés, on trouve ça :

Et ce photo-là, je la reconnais bien, c'est la photo de la machine à café de mon travail ! La photo a été prise par mon collègue Fred le premier avril 2008, juste après que j'ai trafique un peu la machine pour faire un poisson d'avril.
C'est aussi Fred qui a trouvé la photo sur ASI...
Voici la photo telle que je l'avais posté ce premier avril 2008 :

Je parie qu'ils ont trouvé la photo sur Google Images et que sans trop se poser des questions, l'ont pris pour l'article.
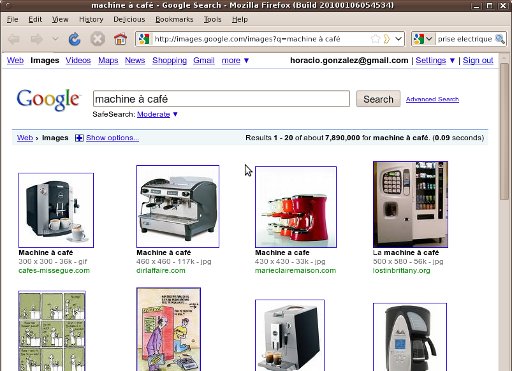
Pourtant la photo, comme toutes celles que je mets sur le blog, est sous licence Creative Commons. Légalement, ils ont le droit de l'utiliser, la seule chose que la licence leur demande, c'est de citer la source !
C'est trop demander pour un média internet qui se dit sérieux de citer les sources des images qu'il utilise ?
Mise à jour
De la même façon que j'ai été rapide ce matin pour me plaindre, je me dois aussi d'être rapide pour raconter la suite.
Arrêt Sur Images a agit avec rapidité et efficacité, ce soir ils m'ont répondu par Twitter :
@LostInBrittany Désolé, vous avez raison. La source a été rajoutée sous la photo, dans les deux articles.
La seule chose que j'ai à redire c'est la façon comme ils indiquent la source :
C'est lostin brittany mais LostInBrittany, mais cela n'est que du détail. Par contre, ce n'est pas © mais CC, et cela est plus important dans la forme...
Mais bon, l'important c'est qu'ils ont réagi assez rapidement, et qu'ils ont montré qu'ils sont à l'écoute et qu'ils sont des professionnels capables de rectifier. Chapeau !
Joyeux anniversaire, Apache !

En 1995 le web était bien différent à celui qu'on connaît aujourd'hui. Très peu de sites web (l'immense majorité desquels étaient des sites d'universités et des centres de recherche), peu de serveurs web (presque exclusivement le vénérable NCSA HTTPd), peu de navigateurs (Mosaic et un nouveau venu appelé Netscape Navigator) et peu d'utilisateurs (des universitaires, des chercheurs, des geeks de la première heure).
Et c'est dans ce terrain que le 23 février 1995 apparait la première version d'un logiciel qui allait jouer un rôle clé dans l'expansion grand public du web : le serveur web Apache HTTP Server.
Conçu initialement comme un fork du NCSA HTTPd censé corrigé des bugs de celui-ci, Apache HTTP Server est vite devenu le serveur web de référence, ayant encore aujourd'hui une part de marché de plus de 50%.
C'est donc aujourd'hui 23 février 2010, que Apache HTTP Server fête son 15ème anniversaire.

Joyeux anniversaire, Apache !
Vous pouvez lire plus de choses sur l'histoire d'Apache HTTP Server sur le site de la fondation Apache.
En vrac et en retard

Depuis une bonne dizaine de jours, je n'ai pas réussi a trouver du temps pour m'asseoir devant l'ordinateur et bloguer tranquillement. Pourtant ce n'est pas l'envie qui m'a manqué, ni l'absence de sujets sur lesquels bloguer, mais bon...
Il y avait surtout deux sujets sur lesquels j'aurais voulu bloguer : Google OS et la disparition de l'idée d'URL qui risque de transformer le web dans un Minitel ou une TV 2.0. Ce matin, en faisant ma revue de blogs (que j'avais aussi pas mal négligée), je suis tombé sur deux articles de Tristan Nitot sur ces mêmes sujets, deux articles qui coincident presque à 100% avec mon avis.
Comme ce soir je n'ai pas trop le temps, je vous laisse simplement les liens vers les deux articles à Tristan Nitot. Les liens des deux articles méritent bien le détour (comme c'est souvent le cas avec les billets de Standblog...).
- Actu bidouillabilité, où il parle de la menace que la disparition de l'URL signifie pour l'internet comme on la connaît.
- Présentation de Google Chrome OS, avec une petite présentation du nouveau OS de Google, ouvert ma non troppo...
Amazon, 1984 et les DRM : les excuses du PDG
Le dérapage orwelien d'Amazon a eu un dernier épisode ce weekend lorsque le PDG d'Amazon, Jeff Bezos a reconnu publiquement l'erreur, il a assuré qu'une telle action ne se reproduira plus et il a demandé pardon à ses clients :
This is an apology for the way we previously handled illegally sold copies of 1984 and other novels on Kindle. Our "solution" to the problem was stupid, thoughtless, and painfully out of line with our principles. It is wholly self-inflicted, and we deserve the criticism we've received. We will use the scar tissue from this painful mistake to help make better decisions going forward, ones that match our mission.
With deep apology to our customers,
Jeff Bezos
Founder & CEO
Amazon.com
C'est rare qu'une compagnie présente c'est excuses aux clients, et c'est encore plus rare que cela se fasse directement par la bouche du PDG. Mais ce qui est encore plus rare, c'est que ces excuses soient si claires, si peu nuancées, sans langue de bois : notre solution au problème était stupide, irréfléchie, et complètement en désaccord avec nos principes. Comme quoi chez Amazon ils n'ont pas oublie que la clé de leur succès a toujours été placer le client au centre.
Je suis bien prêt à croire la sincérité de ces excuses, et je suis à un peu près sûr de qu'un tel épisode ne se reproduira plus. Mais je ne peux pas m'empêcher de penser que rien de tout ça ne serait pas arrivé si Amazon n'était pas parti d'un modèle défectueux, celui d'une plate-forme remplie de verrous numériques et rendant possible l'accès et la prise de contrôle à distance par le fabricant.
Ils ne le feront peut-être plus, ils abuseront pas du pouvoir qu'ils ont sur le terminal et son contenu, mais ils pourront toujours le faire. Et tant que ça sera le cas, tant qu'ils auront des DRM partout, le Kindle ne sera pas une vraie alternative au livre traditionnel. Dans un moment où même Apple a renoncé aux DRM pour leur iTunes, je ne pense pas qu'Amazon puisse continuer longtemps à ignorer le problème...
Amazon, 1984 et les DRM
Imaginez que vous achetez un bouquin dans votre libraire favorite. Vous amenez le livre chez vous, vous le placez dans votre étagère et vous partez tranquillement au boulot. Pendant ce temps là, le libraire décide qu'il ne veut plus vendre ce bouquin, et que vous l'avoir vendu a été une erreur. Il va donc chez vous, il se glisse par une fenêtre, il prend le livre de votre étagère et il le garde dans sa poche. Ensuite, il vous laisse à la place un chèque pour le montant que vous aviez payé et une petite note vous expliquant qu'il ne souhaite plus vous vendre le bouquin. Lorsque vous rentrez chez vous le soir, vous constatez avec surprise que le livre n'est plus là et vous voyez le chèque et la note. J'imagine que la plupart d'entre vous qualifierait ça de vol, non ?
Et bien, c'est ça ce qu'Amazon (pourtant une compagnie qui se targe de toujours placer le client au centre de leur stratégie) a fait la semaine dernière avec deux titres de leur catalogue de livres électroniques. Les clients Amazon qui avaient acheté ces livres pour leur Kindle ont eu la désagréable surprise de voir comment leurs livres électroniques avaient disparu de l'appareil, car l'éditeur avait demandé à Amazon de les retirer du marché.
Depuis la sortie du Kindle, Amazon a voulu nous faire croire que le livre électronique avait toutes les avantages du livre papier et aucun des inconvénients. Mais tout en disant ça, ils ont chargé leur système de verrous électroniques qui empêchent par exemple de prêter le livre à un collègue, ou le revendre après l'avoir lu, ou simplement l'offrir à une bibliothèque ou une association, des choses qu'on a fait avec des vrais livres depuis que le bon vieux Guttemberg a imprimé sa première Bible.
Mais là, Amazon a montré définitivement que leur Kindle est tout sauf une alternative au livre papier. Car du moment où ils peuvent se permettre de se connecter à mon Kindle et d'effacer les livres que j'ai acheté, cela me fait perdre toute la foi dans leur système.
Depuis, Amazon a essayé d'expliquer leur geste et ils ont promis qu'ils ne le feraient plus, mais la confiance a été brisé. Et on sait bien qu'une boîte comme Amazon se base sur la confiance des clients, confiance qu'une fois perdue, est difficile à regagner.
Pour ajouter une pointe ironique à l'affaire, il se trouve que les deux titres concernés par cet exemple de big brotherisme sont 1984 et La ferme des animaux. Comme quoi des fois la réalité dépasse la fiction...
1984 est l'un de mes romans favoris. Je l'ai relu récemment, et la relecture m'a mis très mal à l'aise, car je n'ai pas pu m'empêcher de faire des parallélismes avec notre société actuelle. En 1984, le gouvernement efface tout document concernant des faits qu'il souhaite faire oublier, les brulant dans un trou de mémoire, car une fois toute trace disparu, c'est comme si les faits n'avaient jamais existé. Juste comme les livres sur le Kindle.
Appeler des web services depuis le shell
Après l'humour geek, revenons à un billet un peu plus technique...
Je l'ai dit souvent, et je le répète, internet arrivera toujours à me surprendre.
Hier je discutais avec de collègues sur comment faire communiquer un script shell avec une application web en Java sur l'intranet. La solution la plus simple était sans doute de faire un point d'entrée sur l'application Java, une petite servlet à laquelle on appellerait depuis le script shell via wget ou curl.
Quelqu'un a suggéré, à moitié en blaguant, d'implémenter la communication sur la forme d'un vrai web service (WS) en SOAP, avec son WSDL et tout. Je ne vais pas rentrer dans les avantages ou les inconvénients des WS en SOAP vs une approche REST, car c'est un peu philosophique comme débat. Il suffit de dire que pour ce petit besoin c'était un peu exagéré de devoir implémenter un WS SOAP, et on est donc partie sur l'approche REST avec une simple appelle sur l'URL de la servlet.
Ce matin le sujet est revenu dans la conversation et je me suis mis à penser comment on aurait pu faire si on avait eu vraiment besoin d'utiliser des WS complexes, avec SOAP, sécurité, cryptage.... Dans ma tête il aurait fallu développer le client WS à part, en Java par exemple, et appeler ce client depuis mon script shell.
Et là, je me suis dit qu'à coup sûr il y aurait quelqu'un sur le net qui a implémenté un client WS SOAP fait pour être appelé depuis en ligne de commandes, une sorte de wget pour des appels webservice. Un passage rapide par Google m'a permit de confirmer mon intuition, il y en a bien des implémentations de clients SOAP utilisables depuis un script shell !
Je suis allé donc voir WSF/C, un framework pour des WS écrit en C standard, compatible avec les implémentations Apache WS-* (dont Axis2). Ce framework inclut un client WS en ligne de commandes, [wsclient](http://wso2.org/library/3362), que on peu utiliser d'une façon semblable à wget ou curl.
L'implémentation est assez complète, pouvant supporter des différentes schémas d'authentification et cryptage. Le programme se pilote depuis la ligne de commandes, d'une façon assez simple pour ceux habitués à utiliser des programmes sur le shell.
Par exemple, pour appeler les WS Amazon, il suffit de faire :
:~$ wsclient --soap1.1 --no-mtom --action http://soap.amazon.com
:~$ http://soap.amazon.com:80/onca/soap?Service=AWSECommerceService < item_search.xml
où item_search.xml est un fichier XML respectant le format SOAP des WS Amazon. Par exemple :
<ItemSearch xmlns="http://webservices.amazon.com/AWSECommerceService/2005-10-05">
<AWSAccessKeyId>Access Key</AWSAccessKeyId>
<Request>
<ResponseGroup>Medium</ResponseGroup>
<ItemPage>1</ItemPage>
<Keywords>Web Services</Keywords>
<SearchIndex>Books</SearchIndex>
</Request>
</ItemSearch>
Est-ce que c'est utile ? Peut-être pas pour une utilisation quotidienne, mais lorsqu'on veut faire des tests sur un serveur n'ayant pas d'interface graphique (ne pouvant donc pas utiliser des outils telles que SoapUI), c'est une façon beaucoup plus rapide, simple et sympa que devoir tout faire avec curl ou devoir programmer un client Java pour le faire.
Bref, un petit outil curieux pour garder sous la main au cas où on pourrait en avoir besoin...
Pages jaunes ou le spam offline

La semaine dernière, en ouvrant ma boîte à lettres, j'y ai trouvé les deux gros volumes des Pages Jaunes et Pages Blanches, une année de plus. Sur le coup, je n'ai pas eu la présence d'esprit de le jeter dans la corbeille de recyclage avec les autres encarts publicitaires, et je l'ai monté chez moi, où il a fini dans un coin.
Chaque année je m'étonne de voir comment Pages Jaunes continue à distribuer massivement ses annuaires, fermant les yeux au fait que la plupart de ces annuaires ne seront ouverts même pas une fois. Et cette année, cet étonnement à viré en dégoût face à cette pratique abusive.
Comme pour la plupart des gens que je connais, ça fait déjà des années que les Pages Jaunes en papier ne me servent plus à rien. Si je veux un numéro de téléphone ou une adresse, mon premier réflexe est aller sur le net et le chercher, souvent sur pagesjaunes.ft d'ailleurs. L'idée de prendre les Pages Jaunes papier et d'y chercher quelque chose ne me vient même pas à l'esprit.
Et ce n'est pas que moi avec mon côté geek, c'est quelque chose de général. A l'heure où la plupart de foyers sont équipés d'internet, l'utilisation d'un annuaire papier devient aussi marginale que celle des cassettes audio ou des films en VHS.
Du gaspillage
Je ne suis pas écologiste, loin de là, mais je ne peux pas m'empêcher de trouver dégouttant le gaspillage en temps, ressources et argent qui représentent ces annuaires papier. Des milliers de tons de papier et des litres d'eau et d'encre, des tonnes de CO2 et d'autres polluants émisses par les imprimeries et par les camions qui les acheminent, des centaines d'heures de travail pour mettre en page l'annuaire département par département...
Et tout ça, pour quoi faire ? Pour rester quelques mois posés sur un meuble, encore dans leur plastique, jusqu'au jour où, les derniers scrupules vaincus, ils seront amenés à la déchetterie (dans le meilleur de cas) ou simplement jetés à la poubelle.
Ils sont forts chez Pages Jaunes, ils ont inventé le spam offline...
La meilleure analogie que je peux trouver pour cette distribution massive des Pages Jaunes papier est le spam. Comme les spammers, chez Pages Jaunes envoient des millions d'annuaires à des personnes qui ne les ont pas demandé, en encombrant leurs boîtes à lettres avec des gros volumes de papier qui ne seront jamais utilisés.
Ce qui me trottinait dans l'esprit, c'était le but de ce spam. Je ne peux pas croire que chez Pages Jaunes ils ne sont pas au courant de l'inutilité de ces annuaires papier. Et je ne peux pas croire qu'ils engagent des sommes aussi faramineuses pour quelque chose d'inutile.
Ca serait tellement plus simple de mettre en place un système opt-in et ne distribuer les Pages Jaunes papier qu'à ceux qui les demandent.Pourquoi ils ne le font pas ? La réponse est simple, je le crains bien : avec un tel système, je doute qu'ils arriveraient à distribuer même un 10% des chiffres actuelles, et cela mettrait en évidence l'inutilité de leur produit.
Alors ils vaut mieux fermer les yeux et spammer tout le monde, pour que les annonceurs (des PME, artisans et professions libérales pour la plupart) qui payent pour voir leur nom sur l'annuaire ne mettent pas en doute leur investissement.
Si j'ai raison, ça serait plutôt navrant, non ?
Hadopi et le billet qui ne fût pas




Black-Out
Comme vous avez peut-être déjà vu, la Quadrature du Net lance une nouvelle campagne de sensibilisation sur le danger qui représente HADOPI.
L'opération s'inspire du black out Néo-Zélandais, pour protester contre cette loi injuste et absurde, qui autorise à déconnecter d'internet les gens de façon arbitraire, sans preuves valables ni procès.

LostInBrittany change donc ces couleurs pour se joindre au black out, et je profite de cette occasion pour vous demander de relayer l'opération. Rendez-vous sur la Quadrature du net pour avoir les dernières informations sur ce black out.
Il faut soutenir cette initiative de la Quadrature du net car, comme Korben l'a bien exprimé, c'est maintenant ou jamais. Une fois la loi passé, on ne pourra qu'a subir les erreurs de procédure, les coupures intempestives, la présomption de culpabilité et es abus relatifs au respect de la vie privée.
Les dangers d'internet

Désinformation et paranoïa
Vous avez sûrement vu la campagne publicitaire lancé le mois dernier par le Secrétariat d’Etat à la Famille. Cette campagne, financée avec l'argent de l'Etat (dont l'argent à nous tous) a été diffuse sur les principales chaines TV, et elle prétend alerter la population sur les dangers potentiels d’Internet.
Et quoi dire encore du très bien informé Frédéric Lefebvre, qui déclamait les dangers du net à l'Assemblée Nationale il n'y a pas si longtemps :
Car, bien sûr, internet regorge de néo-nazis, pornographes, jeux violents et surtout pédophiles. Si j'étais un parent qui ne se connaît pas en ordinateurs, et je faisais confiance à ce spot, je laisserais jamais ma fille s'approcher d'un ordinateur, c'est bien trop dangereux !
A les écouter, il vaudrait mieux débrancher sa box et caser la prise à coup de marteau, seulement ainsi on serait sûrs de qu'aucun pédophile va sortir de la prise pour montrer des lapins aux enfants...
Rapport de l'Université de Harvard
Cependant, cette propagande officielle ne tient pas la route, surtout lorsqu'on a des entités indépendantes et fiables qui fournissent des informations contraires. Le Berkman Center for Internet and Society de l'Université de Harvard vient de publier un rapport sur les dangers d'internet pour les enfants, Enhancing child safety and online technologies.
Ce rapport, disponible en téléchargement gratuit, vient à confirmer ce que la plupart d'entre nous savait déjà : l'alarme sur la pretendue insécurité des enfants sur internet et l'image du net comme une repère de prédateurs sexuels n'est plus qu'une histoire à dormir debout.
La population du net est semblable à la population en général. Il y a une bonne partie des gens normaux, et le petit lot de gens qui ne le sont pas. Sur le net il y a des pédophiles, comme il y en a dans le monde réel, et dans la même proportion.
Ca veut dire qu'il ne faut pas prendre de précautions ? Non, ça veut dire qu'il faut prendre les mêmes précautions qu'on prend dans la vraie vie, qu'il faut apprendre aux enfants à ne pas parler avec des inconnus, ni accepter leurs cadeaux, ni partir avec eux, autant dans le monde physique que dans le net. Mais ça veut surtout dire qu'il ne faut pas sombrer dans la paranoïa. Éduquer ? oui ! Informer ? Bien sûr ! Faire peur et crier à l'alarme social ? Non merci !
Maintenant si seulement quelqu'un pouvait expliquer tout ça à cette chère Nadine Morano ou à l'estimable M. Lefebvre...
Free sans Freebox
Non, Free ne m'a pas encore expédié ma Freebox, mais après plusieurs heures de bricolages variés et trois modems ADSL de testés, j'ai réussi à me connecter à Free.
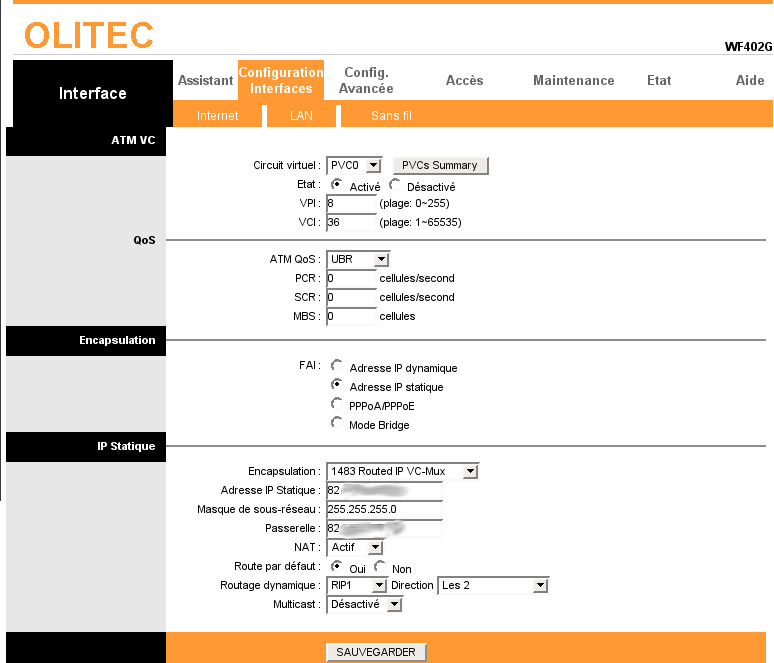
Le tout grâce à un petit Olitec WF402G, dans lequel, après plusieurs essais, j'ai enfin réussi à introduire les bons paramètres pour me connecter au réseau Free dégroupé.
Au cas où vous vous retrouvez dans une situation semblable, je vous laisse ici les paramètres de connexion qui ont marché chez moi. A la base, je me suis basé sur le petit tutoriel de Korben, et j'ai complété les informations qui me manquaient en surfant sur des forums pendant les pauses cafés.
Si vous êtes donc en dégroupage total chez Free et vous voulez vous connecter avec un modem ADSL, les étapes à suivre sont :
-
Trouver un modem récent et débridé
Beaucoup de modems anciens ont de mal à se connecter au réseau Free, il faut les patcher et bidouiller la configuration, par contre avec les modems récents tout devient plus simple. Par modem débridé je veut dire un modem qui ne soit pas attaché à un opérateur, comme c'était le cas de mon AliceBox (où j'avais beau mettre les bons paramètres, elle ne se connectait pas) ou de la Livebox qu'on m'avait prêté (qui n'acceptais que les identifiant commençant par
fti/).Personnellement, je vous recommande un Linksys ou Olitec, au pire on peut les trouver par à peine 40€ dans n'importe quelle grande surface.
-
Récupérer votre adresse IP et l'adresse de la passerelle
Pour cela il suffit de vous connecter sur votre espace perso Free, aller sur "Caractéristiques de ma ligne" et noter votre IP et la passerelle.
-
Configurer le modem
La procèdure exacte dépend de la marque et modèle exact de votre modem, et cela peut requérir des petits ajustements, mais grosso modo il faudra le configurer avec :
- Mode de connexion : adresse IP fixe
- Type de connexion : RFC 1483 Routed ou RFC 1483 Bridged
- VPI : 8
- VCI : 36 (et non 35 comme la plupart des autres FAI)
- Multiplexage : VC/MUX
- Adresse IP :
82.xxx.xxx.xxx(celle que vous avez noté précédemment) - Masque de sous-réseau :
255.255.255.0 - Passerelle :
82.xxx.xxx.xxx(celle que vous avez noté précédemment) - DNS Primaire :
212.27.40.240 - DNS Secondaire :
212.27.40.241
Les serveurs DNS de Free changent souvent, je vous ai indiqué les valeurs valables aujourd'hui, mais ils ne marchent plus au moment où vous essayez, il faudra chercher sur le net les bonnes valeurs.
Dans le cas d'Olitec WF402G, cela donne :
Et voilà, LostInBrittany est de retour !
La vie sans Internet à la maison

Depuis lundi matin je n'ai plus internet chez moi. Et je dois avouer que j'ai du mal à supporter la situation, même si j'essaie de prendre mon mal en patience.
Comme je vous ai déjà raconté, ça fait presque deux ans que j'étais chez Alice ADSL après avoir quitté Numericable suite à des mois de problèmes. Je n'ai pas eu de problème majeur dans ces deux ans chez Alice, et les fois où j'ai eu des soucis, le service technique a été rapide, aimable et compétant.
Cependant, là où la plupart des fournisseurs (surtout Free) enrichissent leurs offres en permanence, Alice n'a rien proposé de nouveau dans ces deux ans. Mêmes tarifs, même débit de 6 Mo, même bouquet télé identique à celui proposé par mon décodeur TNT, même qualité médiocre dans la téléphonie. Et le fait qu'Alice se soit fait acheté par Free il y a quelques mois n'aide pas de tout à résoudre cette situation stagnante.
Alors j'ai décidé de faire le saut et aller directement chez Free. Jeudi dernier je me suis inscrit en ligne, et lundi matin ils ont basculé la ligne... et j'ai perdu mon accès internet.
Ma ligne étant activée chez Free, j'ai essayé toutes les manipulations possibles pour que mon AliceBox se connecte, suivant par exemple ce tutoriel de cher Korben, mais rien n'a marché. J'ai aussi récupéré une vielle Livebox, mais le bridage Wanadoo l'empêchait de se connecter avec mon utilisateur Free. Alors je crois que je suis bon pour attendre que ma Freebox arrive, ce qui ne devrait pas trop tarder.
Enfin, j'espère...